SKEDSOFT
PARSING: A grammar can be used in two ways:
- Using the grammar to generate strings of the language.
- Using the grammar to recognize the strings.
“Parsing” a string is finding a derivation (or a derivation tree) for that string. Parsing a string is like recognizing a string. The only realistic way to recognize a string of a context-free grammar is to parse it.
Exhaustive Search Parsing: The basic idea of the “Exhaustive Search Parsing” is to parse a string w, generate all strings in L and check if w is among them. Problem arises when L is an infinite language. Therefore a systematic approach is needed to achieve this, as it is required to know that no strings are overlooked. And also it is necessary so as to stop after a finite number of steps. The idea of exhaustive search parsing for a string is to generate all strings of length no greater than | w |, and see if w is among them.
The restrictions that are placed on the grammar will allow us to generate any string wÎL in at most 2 | w | – 1 derivation steps. Exhaustive search parsing is inefficient. It requires time exponential in|w|. There are ways to further restrict context free grammar so that strings may be parsed in linear or non-linear time (which methods are beyond the scope of this book). There is no known linear or non-linear algorithm for parsing strings of a general context free grammar.
Top down/Bottomup Parsing: Sequence of rules are applied in a leftmost derivation in Top-down parsing. (Refer to section 2.2.4.) Sequence of rules are applied in a rightmost derivation in Bottom-up parsing. This is illustrated below.
Consider the grammar G with production
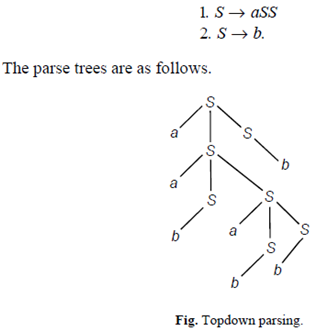
aababbb-> Left parse of the string with the sequence 1121222. This is known as “Topdown Parsing.”
“Right Parse” is the reversal of sequence of rules applied in a rightmost derivation.
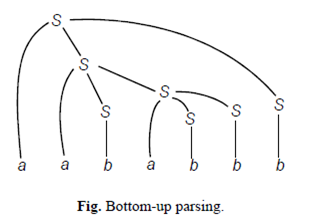
aababbb® Right parse of the string with the sequence 2221121. This is known as “Bottom-up Parsing.”
