SKEDSOFT
Introduction: A huge amount of multimedia data is available on the Web in different forms. These include video, audio, images, pictures, and graphs. There is an increasing demand for effective methods for organizing and retrieving such multimedia data. Compared with the general-purpose multimedia data mining, the multimedia data on the Web bear many different properties. Web-based multimedia data are embedded on the Web page and are associated with text and link information. These texts and links can also be regarded as features of the multimedia data. Using some Web page layout mining techniques (like VIPS), a Web page can be partitioned into a set of semantic blocks. Thus, the block that contains multimedia data can be regarded as a whole. Searching and organizing the Web multimedia data can be referred to as searching and organizing the multimedia blocks.
Let’s consider Web images as an example. Figures 10.7 and 10.9 already show that VIPS can help identify the surrounding text for Web images. Such surrounding text provides a textual description of Web images and can be used to build an image index. The Web image search problem can then be partially completed using traditional text search techniques. Many commercial Web image search engines, such as Google and Yahoo!, use such approaches.
The block-level link analysis technique described in Section 10.5.2 can be used to organize Web images. In particular, the image graph deduced from block-level link analysis can be used to achieve high-quality Web image clustering results.
To construct a Web-image graph, in addition to the block-to-page and page-to-block relations, we need to consider a new relation: block-to-image relation. Let Y denote the block-to-image matrix with dimension nm. For each image, at least one block contains this image. Thus, Y can be simply defined below:
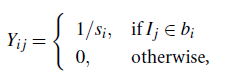
where si is the number of images contained in the image block bi.
Now we first construct the block graph from which the image graph can be further induced. In block-level link analysis, the block graph is defined as:
WB = (1-t)ZX tD-1U;
where t is a suitable constant. D is a diagonal matrix, Dii = ΣjUij.Uij is 0 if block i and block j are contained in two different Web pages; otherwise, it is set to the DOC (degree of coherence, a property of the block, which is the result of the VIPS algorithm) value of the smallest block containing both block i and block j. It is easy to check that the sum of each row of D-1U is 1. Thus, WB can be viewed as a probability transition matrix such that WB (a;b) is the probability of jumping from block a to block b.
Once the block graph is obtained, the image graph can be constructed correspondingly by noticing the fact that every image is contained in at least one block. In this way, the weight matrix of the image graph can be naturally defined as follows:
WI =YTWBY;
where WI is an m X m matrix. If two images i and j are in the same block, say b, then WI (i; j) = WB (b;b) = 0. However, the images in the same block are supposed to be semantically related. Thus, we get a new definition as follows:
WI = tD-1YTY (1-t)YTWBY;
where t is a suitable constant, and D is a diagonal matrix, Dii = Σj(YTY)i j.
Such an image graph can better reflect the semantic relationships between the images. With this image graph, clustering and embedding can be naturally acquired. Figure 10.11(a) shows the embedding results of 1,710 images from the Yahooligans website. Each data point represents an image. Each color stands for a semantic class. Clearly, the image data set was accurately clustered into six categories. As can be seen, the six categories were mixed together and can hardly be separated. This comparison shows that the image graph model deduced from block-level link analysis is more powerful than traditional methods as to describing the intrinsic semantic relationships between WWW images.
