SKEDSOFT
Mining Approximate Frequent Substructures: An alternative way to reduce the number of patterns to be generated is to mine approximate frequent substructures, which allow slight structural variations. With this technique, we can represent several slightly different frequent substructures using one approximate substructure. The principle of minimum description length is adopted in a substructure discovery system called SUBDUE, which mines approximate frequent substructures.
It looks for a substructure pattern that can best compress a graph set based on the Minimum Description Length (MDL) principle, which essentially states that the simplest representation is preferred. SUBDUE adopts a constrained beam search method. It grows a single vertex incrementally by expanding a node in it. At each expansion, it searches for the best total description length: the description length of the pattern and the description length of the graph set with all the instances of the pattern condensed into single nodes. SUBDUE performs approximate matching to allow slight variations of substructures, thus supporting the discovery of approximate substructures.
There should be many different ways to mine approximate substructure patterns. Some may lead to a better representation of the entire set of substructure patterns, whereas others may lead to more efficient mining techniques. More research is needed in this direction.
Mining Coherent Substructures: A frequent substructure G is a coherent subgraph if the mutual information between G and each of its own sub graphs is above some threshold. The number of coherent substructures is significantly smaller than that of frequent substructures. Thus, mining coherent substructures can efficiently prune redundant patterns (i.e., patterns that are similar to each other and have similar support). A promising method was developed for mining such substructures. Its experiments demonstrate that in mining spatial motifs from protein structure graphs, the discovered coherent substructures are usually statistically significant. This indicates that coherent substructure mining selects a small subset of features that have high distinguishing power between protein classes.
Mining Dense Substructures: In the analysis of graph pattern mining, researchers have found that there exists a specific kind of graph structure, called a relational graph, where each node label is used only once per graph. The relational graph is widely used in modeling and analyzing massive networks (e.g., biological networks, social networks, transportation networks, and the World Wide Web). In biological networks, nodes represent objects like genes, proteins, and enzymes, whereas edges encode the relationships, such as control, reaction, and correlation, between these objects. In social networks, each node represents a unique entity, and an edge describes a kind of relationship between entities. One particular interesting pattern is the frequent highly connected or dense subgraph in large relational graphs. In social networks, this kind of pattern can help identify groups where people are strongly associated. In computational biology, a highly connected subgraph could represent a set of genes within the same functional module (i.e., a set of genes participating in the same biological pathways).
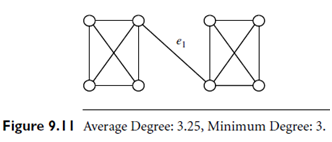 This may seem like a simple constraint-pushing problem using the minimal or average degree of a vertex, where the degree of a vertex v is the numbers of edges that connect v. unfortunately, things are not so simple. Although average degree and minimum degree display some level of connectivity in a graph, they cannot guarantee that the graph is connected in a balanced way. Figure 9.11 shows an example where some part of a graph may be loosely connected even if its average degree and minimum degree are both high. The removal of edge e1 would make the whole graph fall apart. We may enforce the following downward closure constraint: a graph is highly connected if and only if each of its connected sub-graphs is highly connected. However, some global tightly connected graphs may not be locally well connected. It is too strict to have this downward closure constraint. Thus, we adopt the concept of edge connectivity, as follows: Given a graph G, an edge cut is a set of edges Ec such that E(G)-Ec is disconnected. A minimum cut is the smallest set in all edge cuts. The edge connectivity of G is the size of a minimum cut. A graph is dense if its edge connectivity is no less than a specified minimum cut threshold.
This may seem like a simple constraint-pushing problem using the minimal or average degree of a vertex, where the degree of a vertex v is the numbers of edges that connect v. unfortunately, things are not so simple. Although average degree and minimum degree display some level of connectivity in a graph, they cannot guarantee that the graph is connected in a balanced way. Figure 9.11 shows an example where some part of a graph may be loosely connected even if its average degree and minimum degree are both high. The removal of edge e1 would make the whole graph fall apart. We may enforce the following downward closure constraint: a graph is highly connected if and only if each of its connected sub-graphs is highly connected. However, some global tightly connected graphs may not be locally well connected. It is too strict to have this downward closure constraint. Thus, we adopt the concept of edge connectivity, as follows: Given a graph G, an edge cut is a set of edges Ec such that E(G)-Ec is disconnected. A minimum cut is the smallest set in all edge cuts. The edge connectivity of G is the size of a minimum cut. A graph is dense if its edge connectivity is no less than a specified minimum cut threshold.
Now the problem becomes how to mine closed frequent dense relational graphs that satisfy a user-specified connectivity constraint. There are two approaches to mining such closed dense graphs efficiently: a pattern-growth approach called Close- Cut and a pattern-reduction approach called Splat. We briefly outline their ideas as follows.
Similar to pattern-growth frequent itemset mining, CloseCut first starts with a small frequent candidate graph and extend it as much as possible by adding new edges until it finds the largest supergraph with the same support (i.e., its closed supergraph).
- The discovered graph is decomposed to extract sub graphs satisfying the connectivity constraint. It then extends the candidate graph by adding new edges, and repeats the above operations until no candidate graph is frequent.
- Instead of enumerating graphs from small ones to large ones, Splat directly intersects relational graphs to obtain highly connected graphs. Let pattern g be a highly connected graph in relational graphs Gi1 ;Gi2 ; : : :, and Gil (i1 < i2 < : : : < il ). In order to mine patterns in a larger set {Gi1 ;Gi2 ; : : :, Gil , Gil 1}, Splat intersects g with graph Gil 1 . Let g’= g∩Gil 1. Some edges in g may be removed because they do not exist in graph Gil 1. Thus, the connectivity of the new graph g0 may no longer satisfy the constraint. If so, g0 is decomposed into smaller highly connected sub graphs. We progressively reduce the size of candidate graphs by intersection and decomposition operations. We call this approach a pattern-reduction approach.
Both methods have shown good scalability in large graph data sets. Close Cut has better performance on patterns with high support and low connectivity. On the contrary, Splat can filter frequent graphs with low connectivity in the early stage of mining, thus achieving better performance for the high-connectivity constraints. Both methods are successfully used to extract interesting patterns from multiple biological networks.
