SKEDSOFT
Introduction: Multi-relational clustering is the process of partitioning data objects into a set of clusters based on their similarity, utilizing information in multiple relations. In this section we will introduce Cross Clus (Cross-relational Clustering with user guidance), an algorithm for multi relational clustering that explores how to utilize user guidance in clustering and tuple ID propagation to avoid physical joins.
One major challenge in multi-relational clustering is that there are too many attributes in different relations, and usually only a small portion of them are relevant to a specific clustering task. Consider the computer science department database of Figure 9.25. In order to cluster students, attributes cover many different aspects of information, such as courses taken by students, publications of students, advisors and research groups of students, and so on. A user is usually interested in clustering students using a certain aspect of information (e.g., clustering students by their research areas). Users often have a good grasp of their application’s requirements and data semantics. Therefore, a user’s guidance, even in the form of a simple query, can be used to improve the efficiency and quality of high-dimensional multi-relational clustering. Cross Clus accepts user queries that contain a target relation and one or more pertinent attributes, which together specify the clustering goal of the user.
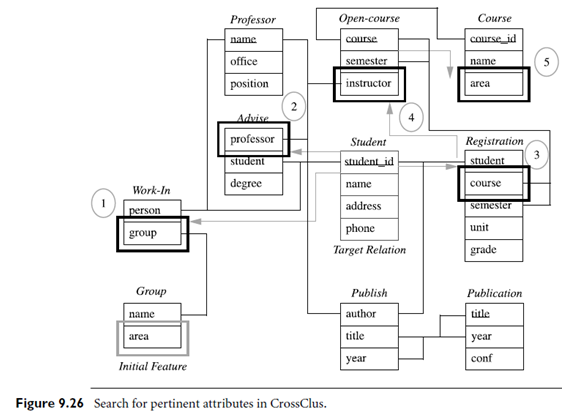
Example: Multi-relational search for pertinent attributes. Let’s look at how Cross-Clus proceeds in answering the query of Example 9.12, where the user has specified her desire to cluster students by their research areas. To create the initial multi-relational attribute for this query, Cross Clus searches for the shortest join path from the target relation, Student, to the relation Group, and creates a multi-relational attribute ˜A using this path. We simulate the procedure of attribute searching, as shown in Figure 9.26. An initial pertinent multi-relational attribute [Student./ Work In ./ Group , area] is created for this query (step 1 in the figure). At first Cross Clus considers attributes in the following relations that are joinable with either the target relation or the relation containing the initial pertinent attribute: Advise, Publish, Registration, Work In, and Group. Suppose the best attribute is [Student./ Advise , professor], which corresponds to the student’s advisor (step 2). This brings the Professor relation into consideration in further search. CrossClus will search for additional pertinent features until most tuples are sufficiently covered. Cross Clus uses tuple ID propagation (Section 9.3.3) to virtually join different relations, thereby avoiding expensive physical joins during its search.
Now that we have an intuitive idea of how CrossClus employs user guidance to search for attributes that are highly pertinent to the user’s query, the next question is, how does it perform the actual clustering With the potentially large number of target tuples, an efficient and scalable clustering algorithm is needed. Because the multi-relational attributes do not forma Euclidean space, the k-medoids method (Section 7.4.1) was chosen, which requires only a distance measure between tuples. In particular, CLARANS (Section 7.4.2), an efficient k-medoids algorithm for large databases, was used. The main idea of CLARANS is to consider the whole space of all possible clusterings as a graph and to use randomized search to find good clusterings in this graph. It starts by randomly selecting k tuples as the initial medoids (or cluster representatives), from which it constructs k clusters. In each step, an existing medoid is replaced by a new randomly selected medoid. If the replacement leads to better clustering, the new medoid is kept. This procedure is repeated until the clusters remain stable.
CrossClus provides the clustering results to the user, together with information about each attribute. From the attributes of multiple relations, their join paths, and aggregation operators, the user learns the meaning of each cluster, and thus gains a better understanding of the clustering results.
