SKEDSOFT
Critical Layers: Even with the tilted time frame model, it can still be too costly to dynamically compute and store a materialized cube. Such a cube may have quite a few dimensions, each containing multiple levels with many distinct values. Because stream data analysis has only limited memory space but requires fast response time, we need additional strategies that work in conjunction with the tilted time frame model. One approach is to compute and store only some mission-critical cuboids of the full data cube.
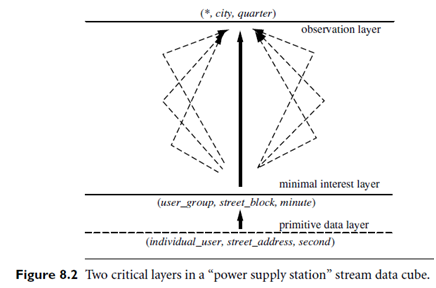
In many applications, it is beneficial to dynamically and incrementally compute and store two critical cuboids (or layers), which are determined based on their conceptual and computational importance in stream data analysis. The first layer, called the minimal interest layer, is the minimally interesting layer that an analyst would like to study. It is necessary to have such a layer because it is often neither cost effective nor interesting in practice to examine the minute details of stream data. The second layer, called the observation layer, is the layer at which an analyst (or an automated system) would like to continuously study the data. This can involve making decisions regarding the signaling of exceptions, or drilling down along certain paths to lower layers to find cells indicating data exceptions.
 Partial Materialization of a Stream Cube: “What if a user needs a layer that would be between the two critical layers?” Materializing a cube at only two critical layers leaves much room for how to compute the cuboids in between. These cuboids can be pre-computed fully, partially, or not at all (i.e., leave everything to be computed on the fly). An interesting method is popular path cubing, which rolls up the cuboids from the minimal interest layer to the observation layer by following one popular drilling path, materializes only the layers along the path, and leaves other layers to be computed only when needed. This method achieves a reasonable trade-off between space, computation time, and flexibility, and has quick incremental aggregation time, quick drilling time, and small space requirements.
Partial Materialization of a Stream Cube: “What if a user needs a layer that would be between the two critical layers?” Materializing a cube at only two critical layers leaves much room for how to compute the cuboids in between. These cuboids can be pre-computed fully, partially, or not at all (i.e., leave everything to be computed on the fly). An interesting method is popular path cubing, which rolls up the cuboids from the minimal interest layer to the observation layer by following one popular drilling path, materializes only the layers along the path, and leaves other layers to be computed only when needed. This method achieves a reasonable trade-off between space, computation time, and flexibility, and has quick incremental aggregation time, quick drilling time, and small space requirements.
To facilitate efficient computation and storage of the popular path of the stream cube, a compact data structure needs to be introduced so that the space taken in the computation of aggregations is minimized. A hyperlinked tree structure called H-tree is revised and adopted here to ensure that a compact structure is maintained in memory for efficient computation of multidimensional and multilevel aggregations.
Each branch of the H-tree is organized in the same order as the specified popular path. The aggregate cells are stored in the non leaf nodes of the H-tree, forming the computed cuboids along the popular path. Aggregation for each corresponding slot in the tilted time frame is performed from the minimal interest layer all the way up to the observation layer by aggregating along the popular path. The step by- step aggregation is performed while inserting the new generalized tuples into the corresponding time slots.
The H-tree ordering is based on the popular drilling path given by users or experts. This ordering facilitates the computation and storage of the cuboids along the path. The aggregations along the drilling path from the minimal interest layer to the observation layer are performed during the generalizing of the stream data to the minimal interest layer, which takes only one scan of stream data. Because all the cells to be computed are the cuboids along the popular path and the cuboids to be computed are the non leaf nodes associated with the H-tree, both space and computation overheads are minimized.
Although it is impossible to materialize all the cells of a stream cube, the stream data cube so designed facilitates fast on-line drilling along any single dimension or along combinations of a small number of dimensions. The H-tree-based architecture facilitates incremental updating of stream cubes as well.
