SKEDSOFT
Huffman codes: Huffman codes are a widely used and very effective technique for compressing data; savings of 20% to 90% are typical, depending on the characteristics of the data being compressed. We consider the data to be a sequence of characters. Huffman's greedy algorithm uses a table of the frequencies of occurrence of the characters to build up an optimal way of representing each character as a binary string.
Suppose we have a 100,000-character data file that we wish to store compactly. We observe that the characters in the file occur with the frequencies given by Figure 16.3. That is, only six different characters appear, and the character a occurs 45,000 times.
| a | b | c | d | e | f | |
|---|---|---|---|---|---|---|
|
|
||||||
| Frequency (in thousands) | 45 | 13 | 12 | 16 | 9 | 5 |
| Fixed-length codeword | 000 | 001 | 010 | 011 | 100 | 101 |
| Variable-length codeword | 0 | 101 | 100 | 111 | 1101 | 1100 |
There are many ways to represent such a file of information. We consider the problem of designing a binary character code (or code for short) wherein each character is represented by a unique binary string. If we use a fixed-length code, we need 3 bits to represent six characters: a = 000, b = 001, ..., f = 101. This method requires 300,000 bits to code the entire file. Can we do better?
A variable-length code can do considerably better than a fixed-length code, by giving frequent characters short codewords and infrequent characters long codewords. Figure 16.3 shows such a code; here the 1-bit string 0 represents a, and the 4-bit string 1100 represents f. This code requires
(45 · 1 13 · 3 12 · 3 16 · 3 9 · 4 5 · 4) · 1,000 = 224,000 bits
to represent the file, a savings of approximately 25%. In fact, this is an optimal character code for this file, as we shall see.
Prefix codes
We consider here only codes in which no codeword is also a prefix of some other codeword. Such codes are called prefix codes. It is possible to show (although we won't do so here) that the optimal data compression achievable by a character code can always be achieved with a prefix code, so there is no loss of generality in restricting attention to prefix codes.
Encoding is always simple for any binary character code; we just concatenate the codewords representing each character of the file. For example, with the variable-length prefix code of Figure 16.3, we code the 3-character file abc as 0·101·100 = 0101100, where we use "·" to denote concatenation.
Prefix codes are desirable because they simplify decoding. Since no codeword is a prefix of any other, the codeword that begins an encoded file is unambiguous. We can simply identify the initial codeword, translate it back to the original character, and repeat the decoding process on the remainder of the encoded file. In our example, the string 001011101 parses uniquely as 0 · 0 · 101 · 1101, which decodes to aabe.
The decoding process needs a convenient representation for the prefix code so that the initial codeword can be easily picked off. A binary tree whose leaves are the given characters provides one such representation. We interpret the binary codeword for a character as the path from the root to that character, where 0 means "go to the left child" and 1 means "go to the right child." Figure 16.4 shows the trees for the two codes of our example. Note that these are not binary search trees, since the leaves need not appear in sorted order and internal nodes do not contain character keys.
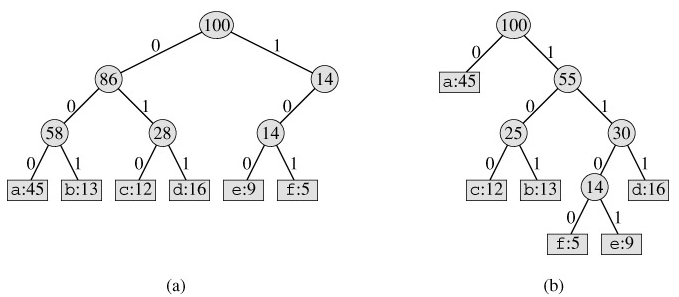
An optimal code for a file is always represented by a full binary tree, in which every nonleaf node has two children. The fixed-length code in our example is not optimal since its tree, shown in Figure 16.4(a), is not a full binary tree: there are codewords beginning 10..., but none beginning 11.... Since we can now restrict our attention to full binary trees, we can say that if C is the alphabet from which the characters are drawn and all character frequencies are positive, then the tree for an optimal prefix code has exactly |C| leaves, one for each letter of the alphabet, and exactly |C| - 1 internal nodes.
Given a tree T corresponding to a prefix code, it is a simple matter to compute the number of bits required to encode a file. For each character c in the alphabet C, let f (c) denote the frequency of c in the file and let dT(c) denote the depth of c's leaf in the tree. Note that dT(c) is also the length of the codeword for character c. The number of bits required to encode a file is thus
which we define as the cost of the tree T.
