SKEDSOFT
Introduction:-Gradient descent procedures are generally used where we want to maximize or minimize n-dimensional functions. The gradient is a vector g that is defined for any differentiable point of a function, that points from this point exactly towards the steepest ascent and indicates the gradient in this direction by means of its norm |g|. Thus, the gradient is a generalization of the derivative for multidimensional functions. Accordingly, the negative gradient −g exactly points towards the steepest descent. The gradient operator  is referred to as Nabla operator, the overall notation of the the gradient g of the point (x, y) of a two dimensional function f being g(x, y) =f(x, y).
is referred to as Nabla operator, the overall notation of the the gradient g of the point (x, y) of a two dimensional function f being g(x, y) =f(x, y).
Let g be a gradient. Then g is a vector with ncomponents that is defined for any point of a (differential) dimensional function f(x1, x2. . . xn). The gradient operator notation is defined as
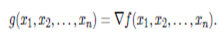
g directs from any point of f towards the steepest ascent from this point, with |g| corresponding to the degree of this ascent.
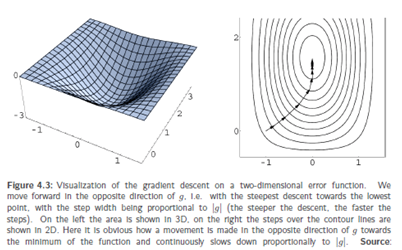
Gradient descent means to going downhill in small steps from any starting point ofour function towards the gradient g (whichmeans, vividly speaking, the direction towhich a ball would roll from the startingpoint), with the size of the steps being proportionalto |g| (the steeper the descent, the longer the steps). Therefore, we moveslowly on a flat plateau, and on a steep ascentwe run downhill rapidly. If we cameinto a valley, we would - depending on thesize of our steps - jump over it or we wouldreturn into the valley across the oppositehillside in order to come closer and closerto the deepest point of the valley by walkingback and forth, similar to our ball movingwithin a round bowl.
Let f be an n-dimensional function and
s = (s1, s2. . . sn) the given starting ‘point.
Gradient descent means going from f(s) against the direction of g, i.e. towards g with steps of the size of |g| towards smaller and smaller values of gradient descent procedures are not an errorless optimization procedure at all however, they work still well on many problems, which makes them an optimization paradigm that is frequently used.
Gradient procedures incorporate several problems: -One problem, is that the result does not always reveal if an error has occurred.
1. Often, gradient descents converge against suboptimal minima.
2. Flat plataeus on the error surface may cause training slowness.
3. Even if good minima are reached, they may be left afterwards.
4. Steep canyons in the error surface may cause oscillations
