SKEDSOFT
Introduction: -Jordan network without a hidden neuron layer for our training attempts so that the output neurons can directly provide input. This approach is a strong simplification because generally more complicated networks are used. But this does not change the learning principle.
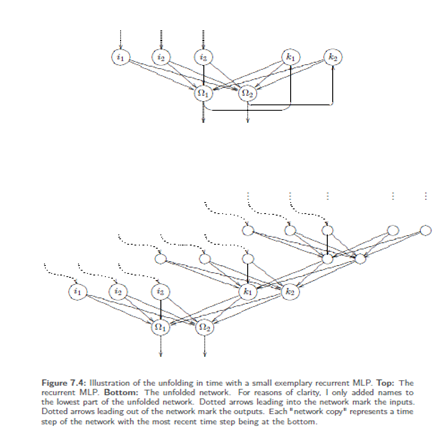
Unfolding in time:-The back propagation of error, which back propagates the delta values. So, in case of recurrent networks the delta values would back propagate cyclically through the network again and again, which makes the training more difficult. On the one hand we cannot know which of the many generated delta values for aweigh should be selected for training, i.e. which values are useful. On the other hand we cannot definitely know when learning should be stopped. The advantage of recurrent networks is great state dynamics within the network; the disadvantage of recurrent networks is that these dynamics are also granted to the training and therefore make it difficult. One learning approach would be the attempt to unfold the temporal states of the network: Recursions are deleted by putting a similar network above the context neurons, i.e. the context neurons are, as a manner of speaking, the output neurons of the attached network. More generally spoken, we have to backtrack the recurrences and place "‘earlier"’ instances of neurons in the network thus creating a larger, but forward-oriented network without recurrences. This enables training a recurrent network with any training strategy developed for non-recurrent ones. Here the input is entered as teaching input into every "copy" of the input neurons. This can be done for a discrete number of time steps. These training paradigms are calledunfolding in time.
After the unfolding training by means of backpropagation of error is possible. But obviously, for one weight wi,j several changing values Δwi,j are received,which can be treated differently: accumulation, averaging etc. A simple accumulation could possibly result in enormous changes per weight if all changes have the same sign. Hence, also the average is not to be underestimated. We could also introduce a discounting factor, which weakens the influence of Δwi,jof the past. Unfolding in time is particularly useful if we receive the impression that the closer past is more important for the network than the one being further away. The reason for this is that back propagation has only little influence in the layers farther away from the output. Disadvantages: the training of such an unfolded network will take a long time since a large number of layers could possibly be produced. A problem that is no longer negligible is the limited computational accuracy of ordinary computers, which is exhausted very fast because of so many nested computations (the farther we are from the output layer, the smaller the influence of back propagation, so that this limit is reached). Furthermore, with several levels of context neurons this procedure could produce very large networks to be trained.
Teacher forcing:-Other procedures are the equivalentteacher forcing and open loop learning. They detach the recurrence during the learning process: We simply that the recurrence does not exist and apply the teaching input to the context neurons during the training. So, back propagation becomes possible, too. Disadvantage: with Elman networks a teaching input for non-output-neurons is not given.
Recurrent back propagation:-Another popular procedure without limited time horizon is the recurrent back propagation.
Training with evolution:-Due to the already long lasting training time, evolutionary algorithms have proved to be of value, especially with recurrent networks. One reason for this is that they are not only unrestricted with respect to recurrences but they also have other advantages when the mutation mechanisms are chosen suitably: So, for example, neurons and weights can be adjusted and the network topology can be optimized With ordinary MLPs, however, evolutionary strategies are less popular since they certainly need a lot more time than a directed learning procedure such as back propagation.
