SKEDSOFT
Alternative Approaches: All the algorithms described in this chapter attempt to provide improved performance over the three commonly used approaches. These approaches are background, polled, and interruptdriven executions. For the sake of simplicity and clarity, we ignore sporadic jobs for now. Background and Interrupt-Driven Execution versus Slack Stealing. According to the background approach, aperiodic jobs are scheduled and executed only at times when there is no periodic or sporadic job ready for execution. Clearly this method always produces correct schedules and is simple to implement. However, the execution of aperiodic jobs may be delayed and their response times prolonged unnecessarily.
As an example, we consider the system of two periodic tasks T1 = (3, 1) and T1 = (10, 4) shown in Figure 7–2. The tasks are scheduled rate monotonically. Suppose that an aperiodic job A with execution time equal to 0.8 is released (i.e., arrives) at time 0.1. If this job is executed in the background, its execution begins after J1,3 completes (i.e., at time 7) as shown in Figure 7–2(a). Consequently, its response time is 7.7.
An obvious way to make the response times of aperiodic jobs as short as possible is to make their execution interrupt-driven. Whenever an aperiodic job arrives, the execution of periodic tasks are interrupted, and the aperiodic job is executed. In this example, A would execute starting from 0.1 and have the shortest possible response time. The problem with this scheme is equally obvious: If aperiodic jobs always execute as soon as possible, periodic tasks may miss some deadlines. In our example, if the execution time of A were equal to 2.1, both J1,1 and J2,1 would miss their deadlines.
The obvious solution is to postpone the execution of periodic tasks only when it is safe to do so. From Figure 7–2(a), we see that the execution of J1,1 and J2,1 can be postponed by 2 units of time because they both have this much slack. (Again, at any time t , the slack of a job with deadline d and remaining execution time e is equal to d − t − e.) By postponing the execution of J1,1 and J2,1, the scheduler allows aperiodic job A to execute immediately after
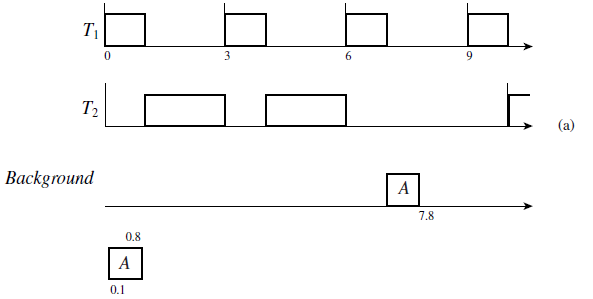
its arrival. The response time of A is equal to 0.8, which is as short as possible. The periodic job J1,1 completes at time 1.8, and J2,1 completes at 7.8. Both of them meet their deadlines. On the other hand, if the execution time of A is 2.1, only the first two units of the job can complete as soon as possible. After A has executed for 2 units of time, periodic tasks have no more slack and must execute. The last 0.1 unit of A must wait until time 9.0 when both periodic tasks have slack again. (We will return in Section 7.6 to explain this example further.)
Algorithms that make use of the available slack times of periodic and sporadic jobs to complete aperiodic jobs early are called slack-stealing algorithms, which were first proposed by Chetto, et al. [ChCh] and Lehoczky, et al. [LeRa]. In systems where slack-stealing can be done with an acceptable amount of overhead, it allows us to realize the advantage of interrupt-driven execution without its disadvantage. We saw in Chapter 5 that slack-stealing is algorithmically simple in clock-driven systems (although it complicates the implementation of clock-driven scheduling considerably). As you will see in Sections 7.5 and 7.6 slack stealing is significantly more complex in priority-driven systems.
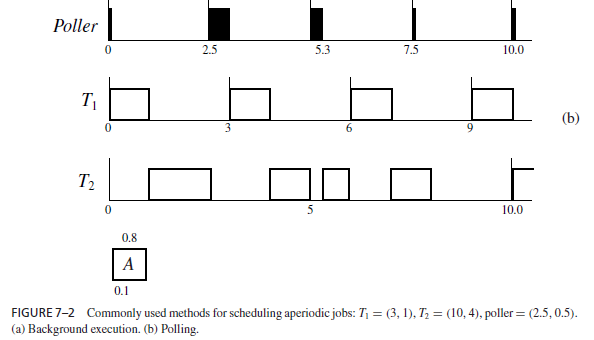
Polled Executions versus Bandwidth-Preserving Servers. Polling is another commonly used way to execute aperiodic jobs. In our terminology, a poller or polling server (ps , es) is a periodic task: ps is its polling period, and es is its execution time. The poller is ready for execution periodically at integer multiples of ps and is scheduled together with the periodic tasks in the system according to the given priority-driven algorithm. When it executes, it examines the aperiodic job queue. If the queue is nonempty, the poller executes the job at the head of the queue. The poller suspends its execution or is suspended by the scheduler either when it has executed for es units of time in the period or when the aperiodic job queue becomes empty, whichever occurs sooner. It is ready for execution again at the beginning of the next polling period. On the other hand, if at the beginning of a polling period the poller finds the aperiodic job queue empty, it suspends immediately. It will not be ready for execution and able to examine the queue again until the next polling period.
We now use the poller as an example to introduce a few terms and jargon which are commonly used in real-time systems literature. We will use them to describe variations of the poller in subsequent sections. We call a task that behaves more or less like a periodic task and is created for the purpose of executing aperiodic jobs a periodic server. A periodic server (ps , es) is defined partially by its period ps and execution time es . (Roughly speaking, the server never executes for more than es units of time in any time interval of length ps . However, this statement is not true for some kinds of servers.) The parameter es is called the execution budget (or simply budget) of the server. The ratio us = es/ps is the size of the server. A poller (ps , es) is a kind of periodic server. At the beginning of each period, the budget of the poller is set to es . We say that its budget is replenished (by es units) and call a time instant when the server budget is replenished a replenishment time.
We say that the periodic server is backlogged whenever the aperiodic job queue is nonempty and, hence, there is at least an aperiodic job to be executed by the server. The server is idle when the queue is empty. The server is eligible (i.e., ready) for execution only when it is backlogged and has budget (i.e., its budget is nonzero). When the server is eligible, the scheduler schedules it with the ready periodic tasks according to the algorithm used for scheduling periodic tasks as if the server is the periodic task (ps , es). When the server is scheduled and executes aperiodic jobs, it consumes its budget at the rate of one per unit time. We say that the server budget becomes exhausted when the budget becomes zero. Different kinds of periodic servers differ in how the server budget changes when the server still has budget but the server is idle. As an example, the budget of a poller becomes exhausted instantaneously whenever the poller finds the aperiodic job queue empty, that is, itself idle.
Figure 7–2(b) shows a poller in the midst of the two fixed-priority periodic tasks T1 = (3, 1) and T2 = (10, 4). The poller has period 2.5 and execution budget 0.5. It is treated by the scheduler as the periodic task (2.5, 0.5) and is given the highest priority among periodic tasks. At the beginning of the first polling period, the poller’s budget is replenished, but when it executes, it finds the aperiodic job queue empty. Its execution budget is consumed instantaneously, and its execution suspended immediately. The aperiodic job A arrives a short time later and must wait in the queue until the beginning of the second polling period when the poller’s budget is replenished. The poller finds A at head of the queue at time 2.5 and executes the job until its execution budget is exhausted at time 3.0. Job A remains in the aperiodic job queue and is again executed when the execution budget of the poller is replenished at 5.0. The job completes at time 5.3, with a response time of 5.2. Since the aperiodic job queue is empty at 5.3, the budget of the poller is exhausted and the poller suspends.
