SKEDSOFT
Introduction:
In many modeling problems of interests, responses are categorical variables, i.e., response levels are discrete and with no natural ordering.
Logistic Regression and Discrete Choice Models:
1. Logistic regression models are a widely used set of modeling procedures for predicting these probabilities.
2. It is particularly relevant for cases in which what might be considered a large number of data points is available. Considering that “data mining” is the analysis or very large flat files, logistic regression can be considered an important data mining technique. Also, “discrete choice models” are logistic regression models in which the levels of the categorical variables are options a decision-maker might select.
3. In these situations, the probability is the market share might command when faced with a specified list of competitors. Logistic regression models including discrete choice models are based on the following concept.
4. Each level of the categorical response is associated with a continuous random variable, which we might call ui for the “utility” of response level i. If the random variable associated with a given level is highest, that level is response or choice.
5. Hera figure (a) and (b) shows a response with two levels, e.g., system options a decision-maker might choose.in (a) System 1 random variables have a lower average than system 2 random variables. However, by chance the realization for system 1 (♦) has a higher value than for system 2 (♦). Then, the response would be system 1 but, in general, system 2 would have a higher probability.
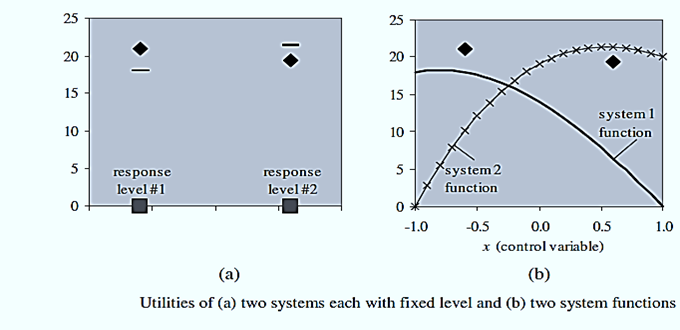
6. (b) shows how the distribution means of the two random variables are functions of a controllable input factor x.
7. By adjusting x, it could be possible to tune each system to its optimum resulting in the highest chance that that level (or
8. system) will occur (or be chosen). Note that the input factor levels that tune one system to its maximum can be different than those that tune another system to its maximum.
9. The goal of experimentation in logistic regression is, therefore, to derive the underlying functions and then to use these functions to predict probabilities.
10. The specific utilities, ui, for each level i are random variables. “Logit models” are logistic regression models based on the assumption that the random utilities follow a so-called “extreme value” distribution.
11. “Probit models” are logistic regression models based on the assumption that the utilities are normally distributed random variables. Sources of randomness in the utilities can be attributed to differences between the average system performance and the actual and/or differences between the individual decision-maker and the average decision-maker.
