SKEDSOFT
The only statistics that must be maintained in the Hoeffding tree algorithm are the counts nijk for the value v j of attribute Ai with class label yk. Therefore, if d is the number of attributes, v is the maximum number of values for any attribute, c is the number of classes, and l is the maximum depth (or number of levels) of the tree, then the total memory required is O(ldvc). This memory requirement is very modest compared to other decision tree algorithms, which usually store the entire training set in memory.
“How does the Hoeffding tree compare with trees produced by traditional decision trees algorithms that run in batch mode?” The Hoeffding tree becomes asymptotically close to that produced by the batch learner. Specifically, the expected disagreement between the Hoeffding tree and a decision tree with infinite examples is at most δ =p, where p is the leaf probability, or the probability that an example will fall into a leaf. If the two best splitting attributes differ by 10% (i.e., ε=R = 0:10), then by Equation (8.4), it would take 380 examples to ensure a desired accuracy of 90% (i.e., δ = 0:1). For d = 0:0001, it would take only 725 examples, demonstrating an exponential improvement in d with only a linear increase in the number of examples. For this latter case, if p = 1%, the expected disagreement between the trees would be at most δ=p = 0.01%, with only 725 examples per node.
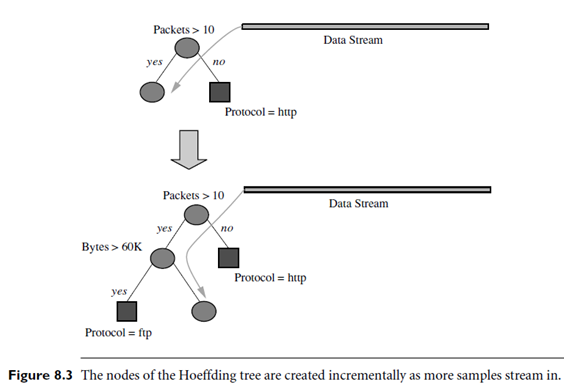
In addition to high accuracy with a small sample, Hoeffding trees have other attractive properties for dealing with stream data. First, multiple scans of the same data are never performed. This is important because data streams often become too large to store. Furthermore, the algorithm is incremental, which can be seen in Figure 8.3 (adapted from [GGR02]). The figure demonstrates how new examples are integrated into the tree as they stream in. This property contrasts with batch learners, which wait until the data are accumulated before constructing the model. Another advantage of incrementally building the tree is that we can use it to classify data even while it is being built. The tree will continue to grow and become more accurate as more training data stream in.
There are, however, weaknesses to the Hoeffding tree algorithm. For example, the algorithm spends a great deal of time with attributes that have nearly identical splitting quality. In addition, the memory utilization can be further optimized. Finally, the algorithm cannot handle concept drift, because once a node is created, it can never change.
