SKEDSOFT
Classification and Prediction: Classification is the process of finding a model (or function) that describes and distinguishes data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label is known).
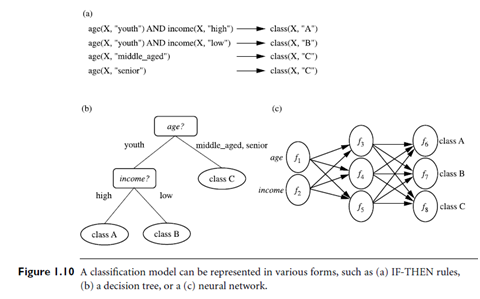
- “How is the derived model presented?” The derived model may be represented in various forms, such as classification (IF-THEN) rules, decision trees, mathematical formulae, or neural networks (Figure 1.10). A decision tree is a flow-chart-like tree structure, where each node denotes a test on an attribute value, each branch represents an outcome of the test, and tree leaves represent classes or class distributions. Decision trees can easily be converted to classification rules. A neural network, when used for classification, is typically a collection of neuron-like processing units with weighted connections between the units. There are many other methods for constructing classification models, such as naïve Bayesian classification, support vector machines, and k-nearest neighbor classification.
- Whereas classification predicts categorical (discrete, unordered) labels, prediction models continuous-valued functions. That is, it is used to predict missing or unavailable numerical data values rather than class labels. Although the term prediction may refer to both numeric prediction and class label prediction, in this book we use it to refer primarily to numeric prediction. Regression analysis is a statistical methodology that is most often used for numeric prediction, although other methods exist as well. Prediction also encompasses the identification of distribution trends based on the available data.
Classification and prediction may need to be preceded by relevance analysis, which attempts to identify attributes that do not contribute to the classification or prediction process. These attributes can then be excluded.
 Example:Classification and prediction. Suppose, as sales manager of All Electronics, you would like to classify a large set of items in the store, based on three kinds of responses to asales campaign: good response, mild response, and no response. You would like to derive a model for each of these three classes based on the descriptive features of the items, such as price, brand, place made, type, and category. The resulting classification should maximally distinguish each class from the others, presenting an organized picture of the data set. Suppose that the resulting classification is expressed in the form of a decision tree. The decision tree, for instance, may identify price as being the single factor that best distinguishes the three classes. The tree may reveal that, after price, other features that help further distinguish objects of each class fromanother include brand and place made. Such a decision tree may help you understand the impact of the given sales campaign anddesign a more effective campaign for the future.
Example:Classification and prediction. Suppose, as sales manager of All Electronics, you would like to classify a large set of items in the store, based on three kinds of responses to asales campaign: good response, mild response, and no response. You would like to derive a model for each of these three classes based on the descriptive features of the items, such as price, brand, place made, type, and category. The resulting classification should maximally distinguish each class from the others, presenting an organized picture of the data set. Suppose that the resulting classification is expressed in the form of a decision tree. The decision tree, for instance, may identify price as being the single factor that best distinguishes the three classes. The tree may reveal that, after price, other features that help further distinguish objects of each class fromanother include brand and place made. Such a decision tree may help you understand the impact of the given sales campaign anddesign a more effective campaign for the future.
Suppose instead, that rather than predicting categorical response labels for each store item, you would like to predict the amount of revenue that each item will generate during an upcoming sale at AllElectronics, based on previous sales data. This is an example of (numeric) prediction because the model constructed will predict a continuous-valued function, or ordered value.
