SKEDSOFT
Thus, the objective function in LPI incurs a heavy penalty if neighboring point’s xi and xj are mapped far apart. Therefore, minimizing it is an attempt to ensure that if xi and xj are “close” then yi (= aT xi) and y j (= aT xj) are close as well. Finally, the basic functions of LPI are the eigenvectors associated with the smallest eigen values of the following generalized eigen-problem:
XLXT a = lXDXT a:
LSI aims to find the best subspace approximation to the original document space in the sense of minimizing the global reconstruction error. In other words, LSI seeks to uncover the most representative features. LPI aims to discover the local geometrical structure of the document space. Since the neighboring documents (data points in high dimensional space) probably relate to the same topic, LPI can have more discriminating power than LSI. Theoretical analysis of LPI shows that LPI is an unsupervised approximation of the supervised Linear Discriminant Analysis (LDA). Therefore, for document clustering and document classification, we might expect LPI to have better performance than LSI. This was confirmed empirically.
Probabilistic Latent Semantic Indexing
The probabilistic latent semantic indexing (PLSI) method is similar to LSI, but achieves dimensionality reduction through a probabilistic mixture model. Specifically, we assume there are k latent common themes in the document collection, and each is characterized by a multinomial word distribution. A document is regarded as a sample of a mixture model with these theme models as components. We fit such a mixture model to all the documents, and the obtained k component multinomial models can be regarded as defining k new semantic dimensions. The mixing weights of a document can be used as a new representation of the document in the low latent semantic dimensions.
Formally, let C = {d1;d2; : : : ;dn} be a collection of n documents. Let θ1; : : : ; θk be k theme multinomial distributions. A word w in document di is regarded as a sample of the following mixture model.
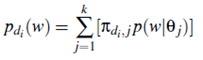
where pdi; j is a document-specific mixing weight for the j-th aspect theme, and Σkj =1 πdi; j = 1.
The log-likelihood of the collection C is
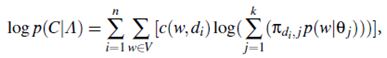
where V is the set of all the words (i.e., vocabulary), c(w;di) is the count of word w in document di, and A=({θj;{πdi;j}ni =1}kj =1) is the set of all the theme model parameters.
The model can be estimated using the Expectation-Maximization (EM) algorithm, which computes the following maximum likelihood estimate:
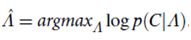
Once the model is estimated, θ1; : : : ; θk define k new semantic dimensions and πdi; j gives a representation of di in this low-dimension space.
