SKEDSOFT
Description:-The speech recognition process is representable as a two-level hierarchical process, consisting of a low level sub words recognition, for example, phoneme recognition, and a high-level—words, sentences, contextual information recognition, language analysis; each of the levels being representable in a recursive manner as many other levels of processing.
Different combinations of techniques for low-level and higher level processing uses the following techniques:-
Template matching and dynamic time warping for low-level processing. Speech recognition using template-matching involves comparing an unclassified input pattern to a dictionary of patterns (templates) and deciding which pattern in the dictionary the input pattern is closest to. Distance measures are used to decide the best match. Before the matching is done it is necessary to perform some time alignment between the input pattern and each reference template. Owing to the variability of speech there will be local and global variations in the time scale of two spoken examples of the same word, regardless of whether the two examples were uttered by the same speaker or not. An effective technique utilized in computer speech recognition for time-aligning two patterns is a nonlinear time-normalizing technique, dynamic time warping. Speech recognition systems based on dynamic time warping have been used successfully for isolated word recognition. Usually the vocabulary is medium-sized or less (i.e., < 100 words) because the dictionary of reference templates takes up a lot of storage space. Dynamic time-warping systems are also usually speaker-dependent. For speaker-independent systems reference templates have to be collected from a large number of people; these are then clustered to form a representative pattern for each recognition unit (Owens 1993). Speech recognition systems utilizing dynamic time warping have also been used for connected speech recognition and recognizing strings of words such as a series of digits (e.g., a telephone number). A limitation of dynamic time warping, when the recognition units are words, is that its time-aligning Capabilities can lead to confusion between words when the principle distinguishing factor is the duration of a vowel, for example, "league" and "Leek.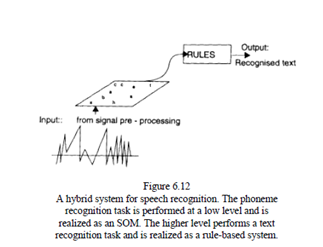
Hidden Markov models for low-level and higher-level processing. Like dynamic time warping, they can account for the variations of speech in time. While dynamic time warping is a template matching technique, hidden Markov models are statistical modeling techniques. A set of training speech data is used to generate probabilistic model. This training can be time-consuming and requires large amounts of memory. However, once trained, the hidden Markov model is fast and requires little memory. The hidden Markov model represents a process with a finite set of states. The states cannot be observed, they are hidden. Each state contains statistical probabilities and functions that perform pattern-matching and time-normalization. The structures of hidden Markov models fall into three major categories: (1) Unconstrained; (2) constrained serial; and (3) constrained parallel.
The constrained serial and constrained parallel models are used for isolated word recognition. They allow for temporal variation because they "move from left to right." Once a state is passed in the constrained serial and constrained parallel models, it cannot be revisited later on. The states in a hidden Markov model are not necessarily physically related to any single observable phenomenon.
The limitations of the hidden Markov models are: poor low-level modeling of speech (at the acoustic-phonetic level), which leads to confusions between acoustically similar words; and poor high-level modeling of speech (semantic modeling), which restricts systems to simple situations where finite state or probabilistic grammars are acceptable. It is difficult to model Linguistic rules directly.
- Neural networks for each of the phases at the low-level and higher-level processing.
- Symbolic Al rule-based systems for higher-level processing.
- Fuzzy systems, mainly for higher-level processing.
Combinations of these techniques lead to more powerful systems. For example, a simple speech recognition system may consist of a low level SOM for phoneme segments classification and a higher-level, rule-based system.
